Hello CUDA!
GPUアーキテクチャとCUDAモデルについて学び、並列ハードウェアがどのように動作するかを理解し、パフォーマンスを最適化します。
はじめに
AI、データサイエンス、またはハイパフォーマンスコンピューティング(HPC)の分野で働いているなら、CUDAという言葉を間違いなく聞いたことがあるでしょう。これはNVIDIAのプラットフォームでありプログラミングモデルであり、GPU内部にある何千もの「コア」のパワーを活用することを可能にします。
AI、特にディープラーニングの爆発的な台頭は、この大規模な並列処理能力と本質的に関連しています。
しかし、CUDAは単なるAPIではありません。これはアルゴリズム設計における新しい視点です。典型的な例:thrust::sort(CUDAライブラリ)は、リニアメモリアクセスを伴う大規模なワークロードにおいて、アーキテクチャやデータにもよりますが、CPUで実行される従来のstd::sortよりも数十倍から数百倍高速になることがあります。
なぜこれほど大きな違いがあるのでしょうか?それは、ハードウェアの動作方法に合わせてアルゴリズムを再設計しているからです。
FlashAttentionからのインスピレーション#
最近の最大のインスピレーションの一つは、Tri Dao氏とFlashAttentionの論文からもたらされました。それ以前は、AIコミュニティはTransformers(GPTなど)のボトルネックは計算律速(compute-bound)、すなわち自己注意(self-attention)のの演算にあると信じていました。
Tri Dao氏は、実際のボトルネックは多くの人が考えていた計算ではなく、メモリ帯域幅であることを示しました。
問題は、GPUが行列乗算(FLOPs)の計算が遅いことではありませんでした。問題は、巨大なQ, K, V行列をGlobal Memory(HBM)からSRAM(超高速オンチップメモリ)へ絶えず読み書きするのに時間がかかりすぎることでした。
FlashAttentionの解決策はKernel Fusion(カーネル融合)です。複数の別個のカーネル(用、 用、 用)を実行し、その都度中間結果をGlobal Memoryに書き込む代わりに、FlashAttentionは一連の操作全体を単一のカーネルで実行します。SRAM/Shared Memoryをキャッシュとして使用してデータを保持し、Global Memoryへのアクセスを最小限に抑えます。
その結果、GPT-2のトレーニングが2〜3倍高速化されました。
この話は、GPUのパフォーマンスを最適化するためには、そのハードウェアとメモリシステムを理解しなければならないという完璧な証拠です。
CUDAとは?#
CUDAは、最新のハードウェアが持つ大規模な並列処理能力を活用・管理するためのプログラミングモデルです。CUDA的な考え方で効果的にプログラミングするためには、ハードウェア、実行モデル、そしてメモリという三つの主要な要素を理解する必要があります。
1. ハードウェア#
私たちは何のためにプログラミングしているのでしょうか?
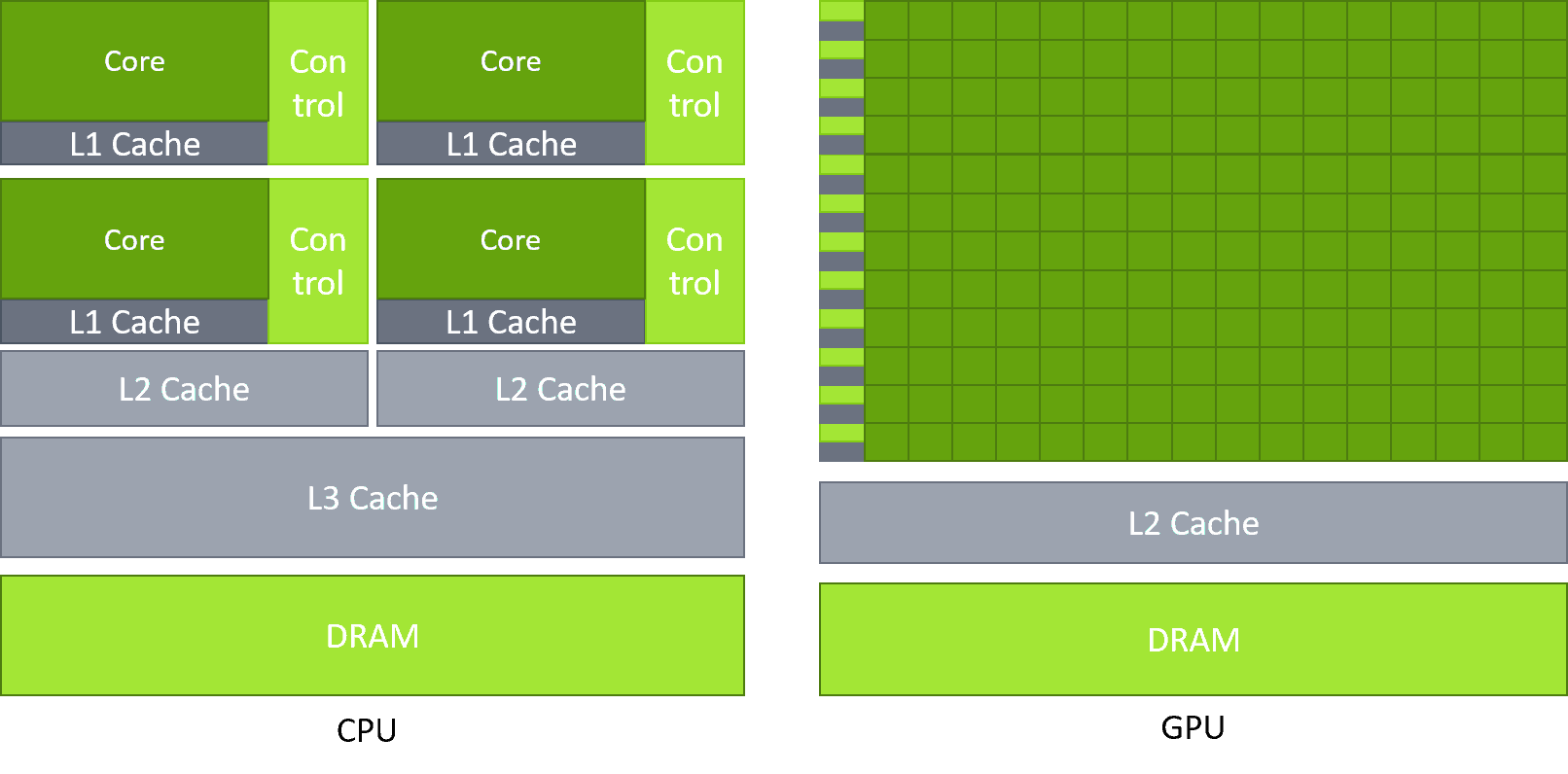
- CPU (Central Processing Unit): 低レイテンシ向けに設計されています。非常にスマートで強力な少数の「コア」を持ち、複雑なタスクを逐次的に、または小規模な並列処理で処理できます。
- GPU (Graphics Processing Unit): 高スループット向けに設計されています。何千ものより単純な「CUDAコア」を持ち、何千もの異なるデータ片に対して同時に同じ操作を実行することに特化しています。
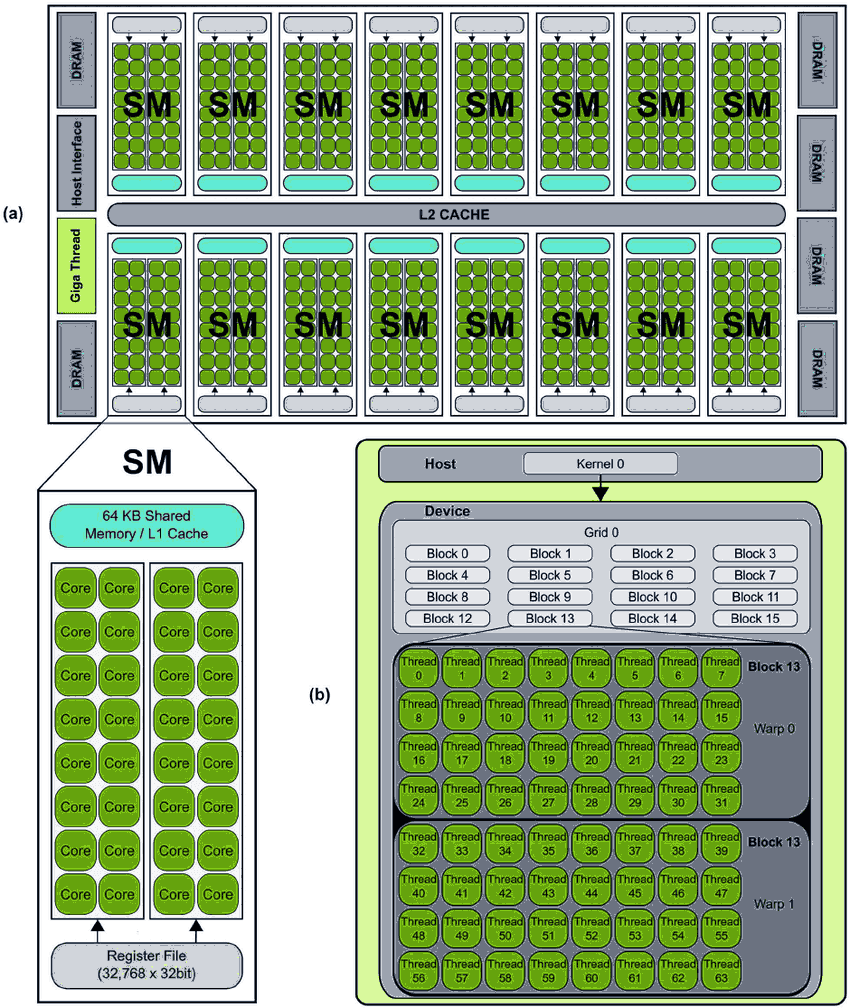
GPUの主要な実行ユニットは SM (Streaming Multiprocessor) です。これはGPUの「心臓部」です。各SMには多数のCUDAコア(例:128コア)が含まれています。
では、並列性はどこから来るのでしょうか?
- Warp: 32スレッドのグループ。これはSMのスケジューリング単位です。
- レイテンシ隠蔽 (Latency Hiding): SMは同時に多数のワープ(例:64の常駐ワープ)を管理します。各クロックサイクルで、SMのワープスケジューラは、CUDAコアによって実行される「準備ができた」ワープを1つ(または複数)選択します。
- シナリオ: Warp 1が操作を実行し、次にGlobal Memoryからデータを読み取る必要があります(非常に遅く、数百サイクル)。「座って待つ」代わりに、SMは即座に(ゼロコストのコンテキストスイッチで)Warp 2(加算を実行中)の実行に切り替えます。次のサイクルで、Warp 2も待機する必要がある場合、Warp 3に切り替わります... というように、SMは数十のワープを循環します。Warp 1に戻る頃には、Global Memoryからのデータがおそらく到着しています。1
注: ほとんどのCUDAパフォーマンス最適化は、warp内の32スレッドの動作を中心に行われます。
2. 実行モデル:Grid、Block、Thread#

プログラマーは数百万のスレッドをどのように編成し、管理するのでしょうか?CUDAは優れた抽象化モデルを提供します:
- Thread: 最小単位であり、カーネル関数(GPUで実行される関数)のコピーを1つ実行します。
- Block: スレッドのグループ(例:128、256、最大1024スレッド)。重要: 同じブロック内のスレッドは、Shared Memoryを介して通信および協調できます。
- Grid: ブロックのグループ。
カーネルを起動するとき、あなたはGPUに次のように伝えています:
// カーネル起動構文
kernel_function<<<GridSize, BlockSize>>>(parameters...);あなたは「GridSize個のブロックからなるGridを作成し、各ブロックはBlockSize個のスレッドを持つように」と言っています。
論理 物理マッピング: Blockはプログラマーにとっての論理的な概念です。ブロックがSMにスケジュールされると、SMはそのブロックを物理的なWarpsに分割します。たとえば、1024スレッドのブロックは、個のワープに分割されます。
各スレッドが自身が誰でどこにいるかを知るために、CUDAは組み込み変数を提供します:blockIdx, threadIdx, blockDim, gridDim。
以下はCUDAの「Hello World」の例です:ベクトル加算 。
// ベクトルAとBを加算し、Cに格納するカーネル
__global__ void vectorAdd(float *A, float *B, float *C, int N) {
// このスレッドのグローバルインデックスを計算
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// スレッドが範囲外にアクセスしないように確認
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
int main() {
// データ初期化、cudaMalloc、cudaMemcpyなどをスキップ...
int N = 1000000; // 100万要素
// ブロックあたり256スレッドを使用
int threadsPerBlock = 256;
// 必要なブロック数を計算
// (N + 255) / 256
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
// カーネル起動!
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, N);
// ...
}3. メモリシステム#
これはパフォーマンスの90%を決定する最も重要な部分です。FlashAttentionで見たように、メモリ管理がすべてです。
GPUは階層的なメモリシステムを持っています。速度が速いほど、容量は小さくなります。
| メモリタイプ | 場所 | 速度 | スコープ | 管理者 |
|---|---|---|---|---|
| レジスタ | オンチップ(SM上) | 最速(~1サイクル) | Threadごと | コンパイラ(自動) |
| Shared Memory / L1 | オンチップ(SM上) | 非常に高速(数サイクル) | Blockごと | プログラマー(__shared__) |
| L2キャッシュ | オンチップ(GPU全体) | 高速 | Grid全体(GPU) | ハードウェア(自動) |
| Global Memory (HBM/VRAM) | オフチップ(カード上) | 非常に低速(~400-800サイクル) | Grid全体(GPU) | プログラマー(cudaMalloc) |
| Constant Memory | オフチップ(オンチップにキャッシュ) | 高速(キャッシュヒット時) | Grid全体(GPU) | プログラマー(__constant__) |
ほとんどのカーネルは、Global Memory(低速)からデータを読み取ることから始まり、そこにデータを書き戻すことで終わります。最適化とは、Shared Memoryとレジスタの使用を最大化することによって、Global Memoryへのアクセスを最小限に抑えることです。
メモリ最適化の2つの中核概念:
- メモリコアレッシング (Memory Coalescing): Global Memoryで発生します。1つのワープ内の32スレッドが同時に32個の連続したメモリ領域(例:
A[idx],A[idx+1], ...,A[idx+31])にアクセスすると、GPUはこれらの32個のリクエストを1回の単一メモリアクセスに統合します。これが理想的なシナリオであり、最大の帯域幅を達成します。1 - バンクコンフリクト (Bank Conflict): Shared Memoryで発生します。Shared Memoryは「バンク」(通常32個)に分割されています。ワープ内の複数のスレッド(例:2スレッド)が、同じバンクに該当する異なるアドレスに同時にアクセスすると、これらのアクセスはシリアル化されます。これにより、並列パフォーマンスが損なわれます。
PGO: 最適化のための方法論#
理論はそうですが、「自分のカーネルがどこで遅くなっているのか」をどうやって知るのでしょうか?
そこで使うのが Profiling-Guided Optimization (PGO)、すなわち「計測 分析 仮説 修正 再計測」という科学的な最適化プロセスです。
ツールを使う前に、分析のための思考モデルが必要です。最も強力で直感的なモデルが Roofline Model(ルーフラインモデル) です。
Roofline Model(GPU)#
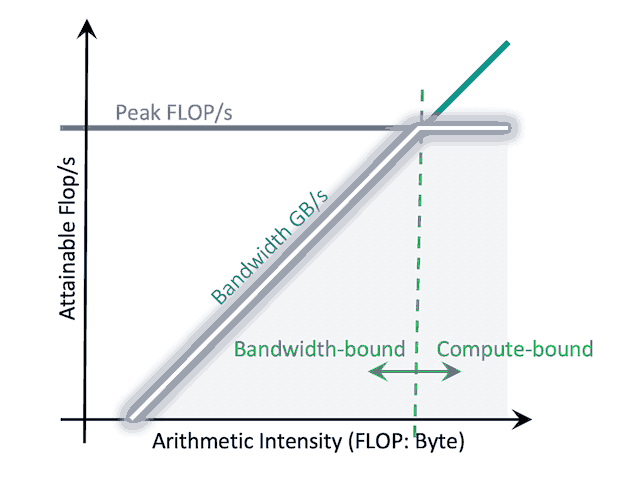
Roofline Model は、特定のハードウェア上でカーネルが理論的に達成できる最大性能を示すグラフです。これにより、「自分のカーネルは 計算性能(compute) に制限されているのか、それとも メモリ帯域幅(memory bandwidth) に制限されているのか?」を即座に判断できます。
このモデルには2つの主要な軸があります:
- Y軸(GFLOPS): 1秒あたりに実行できる浮動小数点演算の数(10億単位)を示します。高いほど良い性能を意味します。
- X軸(Arithmetic Intensity, AI): コア指標であり、FLOPs/Byte で表されます。これは「グローバルメモリから1バイト読み書きするごとに、いくつの演算(FLOPs)を行っているか?」を示します。
Roof(屋根)は2つの部分で構成されています:
- 水平線(Flat Roof): GPUの最大計算性能(Peak GFLOPS)。この限界を超えてカーネルは速く動作できません。
- 斜線(Slanted Roof): メモリ帯域幅の上限(Peak Memory Bandwidth)。カーネルの速度はデータを供給できる速さによって制約されます。
プロファイリングを行うと、カーネルはこのRoofの下に点としてプロットされます。
- その点が斜線の下にある場合(Memory-bound 領域): FlashAttention と同じく、メモリアクセスがボトルネックになっています。最適化するには Arithmetic Intensity を上げる(例:Shared Memory の活用、カーネル融合)ことで、点を右方向に移動させます。
- その点が水平線の下にある場合(Compute-bound 領域): メモリは効率的に使えていますが、今度は計算能力がボトルネックです。最適化するには GFLOPS を上げる(例:Tensor Core の活用、float の代わりに half を使用)必要があります。
Roofline Model は、「何を最適化すべきか」を明確に示すコンパスです。
NVIDIA Nsight#
このデータを収集し、Roofline グラフを描くために使用するのが NVIDIA Nsight ツール群です:
- Nsight Systems: マクロな視点からアプリ全体のタイムラインを可視化します。CPUとGPUの動作、
cudaMemcpy(データコピー)の時間、各カーネルの実行タイミングなどが分かります。どのカーネルを最適化すべきか、I/O がボトルネックかどうかを判断できます。 - Nsight Compute: ミクロな視点で、特定のカーネル内部を詳細に分析します。カーネルが memory-bound か compute-bound かを明確に示し、Occupancy(遅延隠蔽能力)、キャッシュヒット率/ミス率、非コアレス化アクセスの有無などを把握できます。
プロファイリングの後、次のように仮説を立てます:
-
Memory-bound(メモリ制限) の場合:
- 仮説: メモリアクセスが非コアレス化されている。
対応:idxを修正し、32スレッドが連続したアドレスにアクセスするようにする。 - 仮説: 同じデータをグローバルメモリから何度も読み込んでいる。
対応: データを一度 Shared Memory に読み込み、ブロック全体で共有(FlashAttention のように)。
- 仮説: メモリアクセスが非コアレス化されている。
-
Compute-bound(計算制限) の場合:
- 仮説: 不必要に
double(64-bit)を使用している。
対応:float(32-bit)に切り替える。 - 仮説: Tensor Core を使用せずに行列演算を行っている。
対応:cuBLASを使用するか、half(16-bit)/tf32を利用して Tensor Core を有効化する。
- 仮説: 不必要に
-
Latency-bound(低オキュパンシー) の場合:
- 仮説: カーネルが十分な resident warps を持たず、遅延を隠蔽できていない。
原因として、1ブロックあたりのレジスタや共有メモリの使用量が多すぎる可能性がある。
対応: 使用リソースを減らす、またはBlockSizeを調整して1SMあたりのブロック数を増やす。
- 仮説: カーネルが十分な resident warps を持たず、遅延を隠蔽できていない。
結論#
CUDAを学ぶことは、考え方を変える旅です。それは単に新しいAPIを学ぶことではなく、並列ハードウェアのためのアルゴリズムを設計することを学ぶことです。
低速なstd::sortから高速なthrust::sortまで、標準的な自己注意からFlashAttentionまで、それはすべて、実行している「マシン」を理解し、そのルール、特にメモリのルールを尊重した結果です。
この記事が、GPUコンピューティングのエキサイティングな世界の概要を皆さんに提供できたことを願っています。
閲覧数
— 閲覧数
Nguyen Xuan Hoa
nguyenxuanhoakhtn@gmail.com