Hello CUDA!
Tìm hiểu kiến trúc GPU và mô hình CUDA để hiểu cách phần cứng song song hoạt động và tối ưu hóa hiệu năng.
Giới thiệu#
Nếu bạn đang làm việc trong lĩnh vực AI, Khoa học Dữ liệu, hay tính toán hiệu năng cao (HPC), bạn không thể không nghe đến CUDA. Đây là nền tảng (platform) và mô hình lập trình (programming model) của NVIDIA, cho phép chúng ta khai thác sức mạnh của hàng ngàn "lõi" (core) bên trong một GPU.
Sự trỗi dậy mạnh mẽ của AI, đặc biệt là Deep Learning, gắn liền với khả năng xử lý song song khổng lồ này.
Nhưng CUDA không chỉ là một API. Nó là một góc nhìn mới về việc thiết kế thuật toán. Một ví dụ kinh điển: thrust::sort (một thư viện CUDA) trong các workload lớn và truy cập bộ nhớ tuyến tính, có thể nhanh hơn hàng chục đến hàng trăm lần so với std::sort truyền thống chạy trên CPU, tùy thuộc vào kiến trúc và dữ liệu.
Tại sao lại có sự khác biệt kinh khủng đó? Vì chúng ta đang thiết kế lại thuật toán để phù hợp với cách phần cứng vận hành.
Cảm hứng từ FlashAttention#
Một trong những truyền cảm hứng lớn nhất gần đây đến từ Tri Dao và bài báo FlashAttention. Trước đó, cộng đồng AI tin rằng nút thắt cổ chai (bottleneck) của mô hình Transformers (như GPT) nằm ở khả năng tính toán (compute-bound), tức số phép toán của self-attention.
Tri Dao cho thấy bottleneck thực tế lại nằm ở băng thông bộ nhớ, không phải compute như nhiều người từng nghĩ.
Vấn đề không phải là GPU tính toán các phép nhân ma trận (FLOPs) chậm. Vấn đề là việc đọc và ghi các ma trận Q, K, V khổng lồ liên tục từ Global Memory (HBM) ra vào SRAM (bộ nhớ on-chip siêu nhanh) tốn quá nhiều thời gian.
Giải pháp của FlashAttention là Kernel Fusion (hợp nhất kernel). Thay vì chạy nhiều kernel riêng biệt (một cho , một cho , một cho ) và mỗi lần đều phải ghi kết quả trung gian ra Global Memory, FlashAttention thực hiện toàn bộ chuỗi phép toán trong một kernel duy nhất. Nó sử dụng SRAM/Shared Memory như một bộ đệm (cache) để giữ dữ liệu, giảm số lần truy cập Global Memory xuống mức tối thiểu.
Kết quả là tốc độ training GPT-2 tăng gấp 2-3 lần.
Câu chuyện này là minh chứng hoàn hảo: để tối ưu hiệu năng GPU, bạn phải hiểu phần cứng và hệ thống bộ nhớ của nó.
CUDA là gì?#
CUDA là một mô hình lập trình giúp khai thác và quản lý khả năng song song khổng lồ của phần cứng. Để tư duy và lập trình hiệu quả theo mô hình CUDA, chúng ta cần nắm vững ba khía cạnh chính: Phần cứng, Mô hình thực thi, và Bộ nhớ.
1. Phần cứng#
Chúng ta đang lập trình cho cái gì?
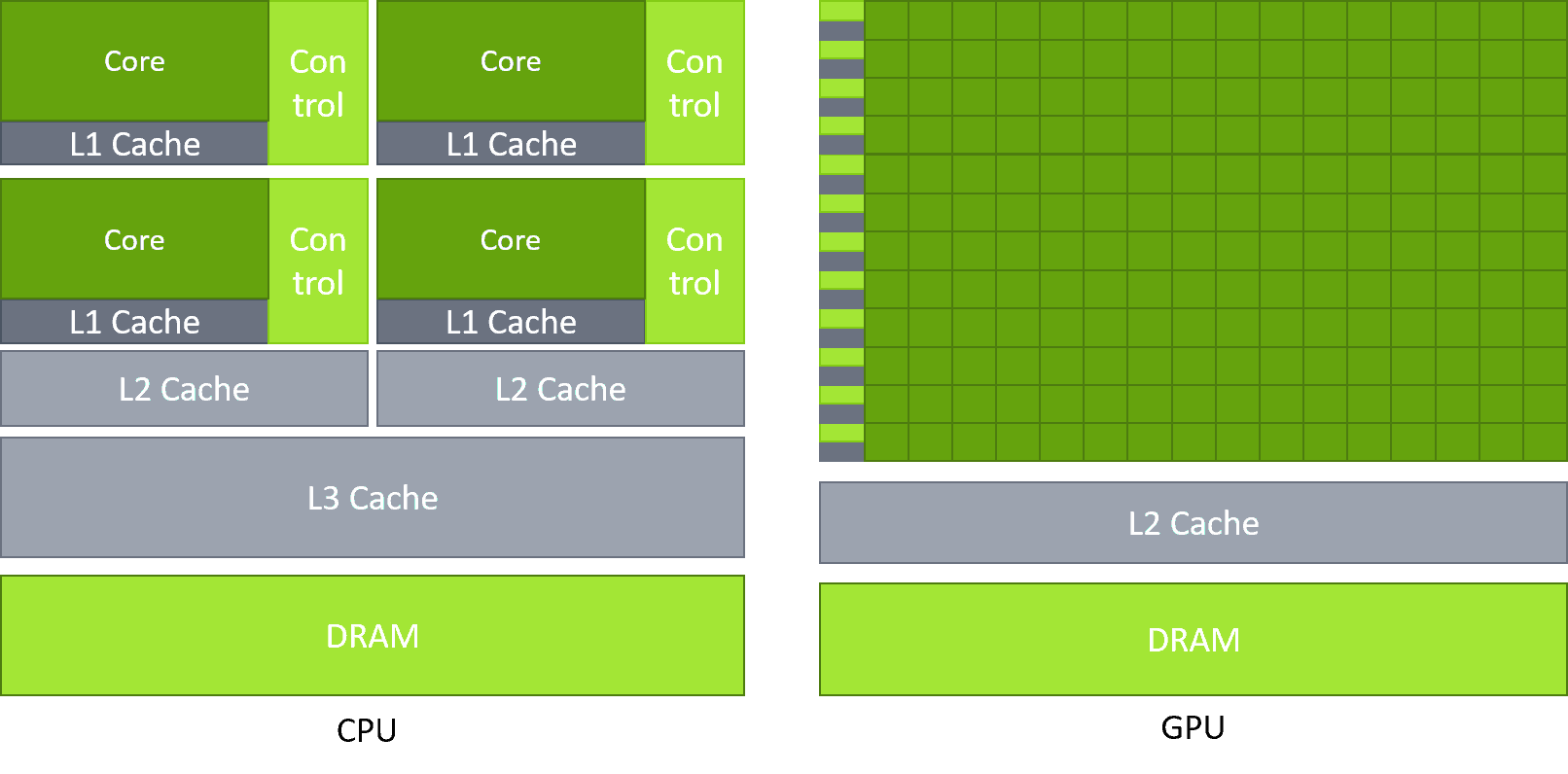
- CPU (Central Processing Unit): Được thiết kế cho độ trễ thấp (low latency). Nó có một vài "lõi" (core) siêu thông minh, mạnh mẽ, có thể xử lý các tác vụ phức tạp một cách tuần tự hoặc song song ở quy mô nhỏ.
- GPU (Graphics Processing Unit): Được thiết kế cho thông lượng cao (high throughput). Nó có hàng ngàn "lõi" (CUDA core) đơn giản hơn, chuyên để thực hiện cùng một phép toán trên hàng ngàn mẩu dữ liệu khác nhau cùng lúc.
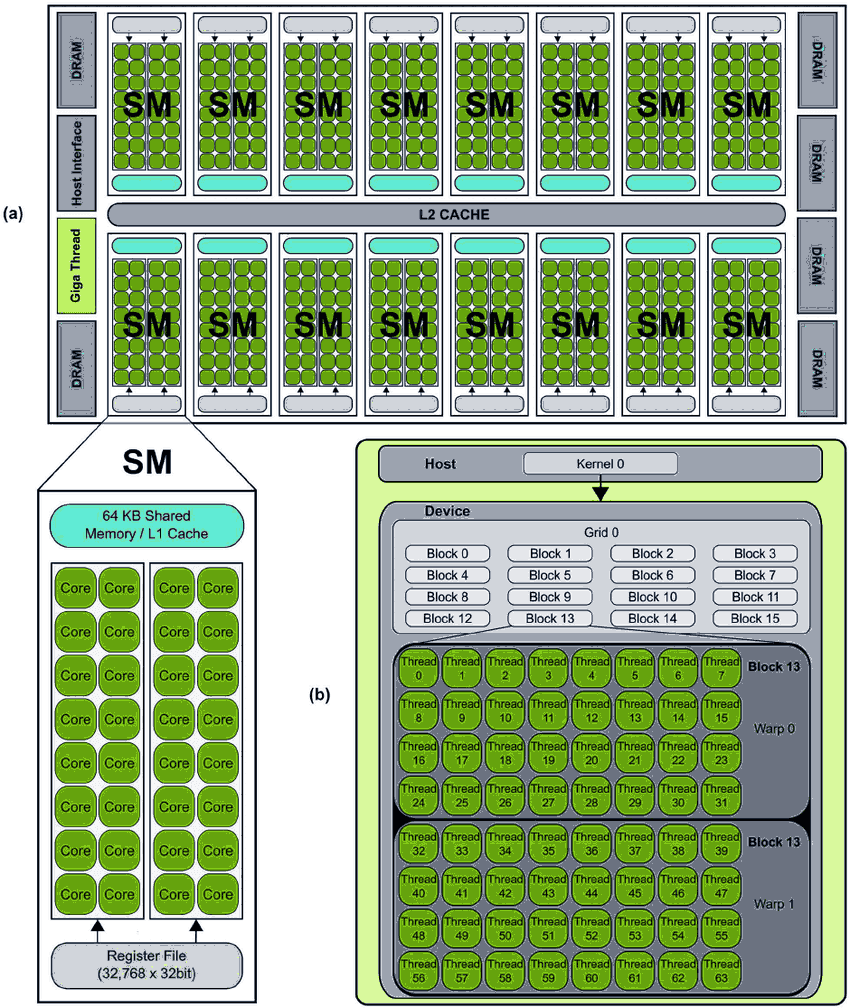
Đơn vị thực thi chính trên GPU là SM (Streaming Multiprocessor). Đây là "trái tim" của GPU. Mỗi SM chứa một số lượng CUDA core (ví dụ: 128 core).
Vậy sự song song đến từ đâu?
- Warp: Một nhóm gồm 32 thread. Đây là đơn vị lập lịch (scheduling) của SM.
- Latency Hiding: Một SM quản lý (manages) đồng thời rất nhiều warp (ví dụ: 64 resident warps). Tại mỗi chu kỳ (clock cycle), bộ lập lịch (Warp Scheduler) của SM sẽ chọn một (hoặc vài) warp đã sẵn sàng (ready) để đưa vào các CUDA core thực thi.
- Kịch bản: Warp 1 thực hiện phép toán, sau đó cần đọc dữ liệu từ Global Memory (rất chậm, mất hàng trăm chu kỳ). Thay vì "ngồi chờ", SM ngay lập tức (zero-cost context switch) chuyển sang thực thi Warp 2 (đang làm phép cộng). Chu kỳ sau, nếu Warp 2 cũng phải chờ, nó chuyển sang Warp 3... Cứ như vậy, SM quay vòng qua hàng chục warp. Đến khi quay lại Warp 1, dữ liệu từ Global Memory có thể đã về đến nơi. 1
Note: Hầu hết các tối ưu hiệu năng CUDA đều xoay quanh hành vi của 32 thread trong một warp.
2. Mô hình thực thi: Grid, Block, Thread#

Làm thế nào để lập trình viên tổ chức và quản lý hàng triệu thread? CUDA cung cấp một mô hình trừu tượng hóa tuyệt vời:
- Thread: Đơn vị nhỏ nhất, thực thi một bản sao của hàm kernel (hàm chạy trên GPU).
- Block: Một nhóm các thread (ví dụ: 128, 256, tối đa 1024 thread). Quan trọng: Các thread trong cùng một block có thể giao tiếp và hợp tác với nhau thông qua Shared Memory.
- Grid: Một nhóm các block.
Khi bạn gọi một kernel, bạn đang ra lệnh cho GPU:
// Cú pháp launch kernel
kernel_function<<<GridSize, BlockSize>>>(parameters...);Bạn đang nói: "Hãy tạo một Grid có GridSize block, mỗi block có BlockSize thread."
Mapping Logic Vật lý: Block là khái niệm logic của lập trình viên. Khi một block được lập lịch lên một SM, SM sẽ chia block đó thành các Warp (vật lý). Ví dụ, một block 1024 thread sẽ được chia thành warp.
Để mỗi thread biết nó là ai và ở đâu, CUDA cung cấp các biến nội tại: blockIdx, threadIdx, blockDim, gridDim.
Dưới đây là ví dụ "Hello World" của CUDA: phép cộng 2 vector .
// Kernel cộng vector A và B, lưu vào C
__global__ void vectorAdd(float *A, float *B, float *C, int N) {
// Tính toán index toàn cục của thread này
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// Đảm bảo thread không truy cập vượt quá mảng
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
int main() {
// Bỏ qua phần khởi tạo dữ liệu, cudaMalloc, cudaMemcpy...
int N = 1000000; // 1 triệu phần tử
// Sử dụng 256 thread mỗi block
int threadsPerBlock = 256;
// Tính số block cần thiết
// (N + 255) / 256
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
// Launch kernel!
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, N);
// ...
}3. Hệ thống bộ nhớ#
Đây là phần quan trọng nhất, quyết định 90% hiệu năng. Như đã thấy từ FlashAttention, quản lý bộ nhớ là tất cả.
GPU có một hệ thống bộ nhớ phân cấp. Tốc độ càng nhanh thì dung lượng càng nhỏ.
| Loại Bộ nhớ | Vị trí | Tốc độ | Phạm vi (Scope) | Ai quản lý? |
|---|---|---|---|---|
| Registers | On-chip (trên SM) | Nhanh nhất (~1 chu kỳ) | Mỗi Thread | Compiler (tự động) |
| Shared Memory / L1 | On-chip (trên SM) | Rất nhanh (vài chu kỳ) | Mỗi Block | Lập trình viên (__shared__) |
| L2 Cache | On-chip (toàn GPU) | Nhanh | Toàn Grid (GPU) | Phần cứng (tự động) |
| Global Memory (HBM/VRAM) | Off-chip (trên card) | Rất chậm (~400-800 chu kỳ) | Toàn Grid (GPU) | Lập trình viên (cudaMalloc) |
| Constant Memory | Off-chip (cache on-chip) | Nhanh (nếu hit cache) | Toàn Grid (GPU) | Lập trình viên (__constant__) |
Hầu hết các kernel đều bắt đầu bằng việc đọc dữ liệu từ Global Memory (chậm) và kết thúc bằng việc ghi dữ liệu ra đó. Tối ưu là việc giảm thiểu truy cập Global Memory, bằng cách tận dụng tối đa Shared Memory và Registers.
Hai khái niệm tối ưu bộ nhớ cốt lõi:
- Memory Coalescing: Xảy ra trên Global Memory. Khi 32 thread trong 1 warp cùng lúc truy cập 32 vùng nhớ liền kề nhau (ví dụ:
A[idx],A[idx+1], ...,A[idx+31]), GPU sẽ gộp 32 yêu cầu này thành 1 giao dịch (transaction) bộ nhớ duy nhất. Đây là kịch bản lý tưởng, đạt băng thông tối đa. 1 - Bank Conflict: Xảy ra trên Shared Memory. Shared Memory được chia thành các "ngân hàng" (banks, thường là 32). Nếu nhiều thread trong 1 warp (ví dụ 2 thread) cùng lúc truy cập vào các địa chỉ khác nhau nhưng lại nằm trên cùng một bank, các truy cập này sẽ bị tuần tự hóa (serialized). Điều này giết chết hiệu năng song song.
PGO: Phương pháp luận để tối ưu#
Lý thuyết là vậy, nhưng làm sao để biết kernel của tôi đang chậm ở đâu?
Chúng ta sử dụng Profiling-Guided Optimization (PGO): một phương pháp luận khoa học: Đo đạc Phân tích Đặt giả thuyết Sửa đổi Đo đạc lại.
Trước khi đi sâu vào công cụ, chúng ta cần một mô hình tư duy để phân tích. Mô hình mạnh mẽ và trực quan nhất chính là Roofline Model.
Roofline Model (GPU)#
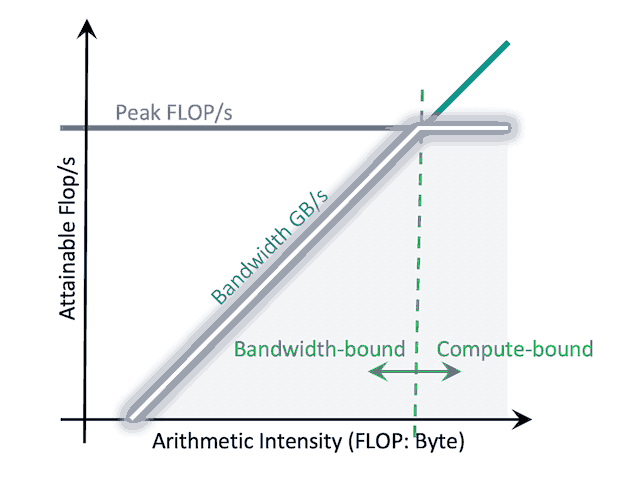
Roofline Model là một biểu đồ cho thấy hiệu năng lý thuyết cao nhất mà kernel của bạn có thể đạt được trên một phần cứng cụ thể. Nó giúp bạn trả lời ngay lập tức câu hỏi: "Kernel của tôi đang bị giới hạn bởi tính toán (compute) hay băng thông bộ nhớ (memory bandwidth)?"
Mô hình này có 2 trục chính:
- Trục Y (GFLOPS): Cho biết bạn thực hiện được bao nhiêu tỷ phép toán dấu phẩy động mỗi giây. Càng cao càng tốt.
- Trục X (Arithmetic Intensity, AI): Đây là chỉ số cốt lõi, đo bằng FLOPs/Byte. Nó trả lời câu hỏi: "Với mỗi Byte dữ liệu bạn đọc/ghi từ Global Memory, bạn thực hiện được bao nhiêu phép toán (FLOPs)?"
Roof có hai phần:
- Đường ngang (Flat Roof): Đây là Giới hạn tính toán (Peak GFLOPS) của GPU. Kernel của bạn không thể chạy nhanh hơn giới hạn này.
- Đường chéo (Slanted Roof): Đây là Giới hạn băng thông bộ nhớ (Peak Memory Bandwidth). Tốc độ của kernel bị giới hạn bởi tốc độ nó có thể đưa dữ liệu vào để xử lý.
Khi bạn profile, kernel của bạn sẽ là một điểm nằm bên dưới Roof này.
- Nếu điểm đó nằm dưới đường chéo (vùng Memory-bound): Vấn đề của bạn giống hệt FlashAttention. Bạn đang bị nghẽn vì đọc/ghi bộ nhớ quá nhiều. Để tối ưu, bạn phải tăng Arithmetic Intensity (ví dụ: dùng Shared Memory, Kernel Fusion) để "di chuyển" điểm này sang bên phải.
- Nếu điểm đó nằm dưới đường ngang (vùng Compute-bound): Bạn đã dùng bộ nhớ hiệu quả, nhưng giờ bạn bị nghẽn ở tốc độ tính toán. Để tối ưu, bạn phải tăng GFLOPS (ví dụ: dùng Tensor Core, dùng phép toán half thay vì float).
Mô hình Roofline cung cấp một la bàn rõ ràng để bạn biết nên tối ưu cái gì.
NVIDIA Nsight#
Để thu thập dữ liệu này và vẽ biểu đồ Roofline, công cụ của chúng ta là bộ NVIDIA Nsight:
- Nsight Systems: Nhìn toàn cảnh (macro). Cho thấy timeline của toàn bộ ứng dụng: CPU làm gì, GPU làm gì,
cudaMemcpy(copy dữ liệu) mất bao lâu, kernel nào chạy khi nào. Nó giúp bạn tìm ra kernel nào đáng để tối ưu, hoặc xem bạn có bị nghẽn ở I/O không. - Nsight Compute: Nhìn chi tiết (micro). Đi sâu vào bên trong một kernel cụ thể. Nó sẽ cho bạn biết chính xác kernel này bị memory-bound hay compute-bound, "Occupancy" (khả năng che lấp độ trễ) bao nhiêu, cache hit/miss rate, có bị uncoalesced access không, v.v.
Sau khi profiling, bạn bắt đầu đặt giả thuyết:
- Nếu Memory-bound (Giới hạn bộ nhớ):
- Giả thuyết: Tôi bị uncoalesced access.
Hành động: Sửa lạiidxđể 32 thread truy cập liền kề. - Giả thuyết: Tôi đang đọc đi đọc lại cùng một dữ liệu từ Global Memory.
Hành động: Tải dữ liệu đó vào Shared Memory một lần, sau đó cho cả block đọc từ Shared Memory (như cách FlashAttention đã làm!).
- Giả thuyết: Tôi bị uncoalesced access.
- Nếu Compute-bound (Giới hạn tính toán):
- Giả thuyết: Tôi đang dùng phép toán
double(64-bit) không cần thiết.
Hành động: Chuyển sangfloat(32-bit). - Giả thuyết: Tôi đang nhân ma trận mà không dùng Tensor Core.
Hành động: Sử dụng thư việncuBLAShoặc lập trình vớihalf(16-bit) /tf32để kích hoạt Tensor Core.
- Giả thuyết: Tôi đang dùng phép toán
- Nếu Latency-bound (Occupancy thấp):
- Giả thuyết: Kernel của tôi không đủ resident warps để che lấp độ trễ. Lý do có thể là tôi dùng quá nhiều register hoặc shared memory cho mỗi block.
Hành động: Giảm tài nguyên sử dụng, hoặc điều chỉnhBlockSizeđể tăng số block có thể trên một SM.
- Giả thuyết: Kernel của tôi không đủ resident warps để che lấp độ trễ. Lý do có thể là tôi dùng quá nhiều register hoặc shared memory cho mỗi block.
Lời kết#
Học CUDA là một hành trình thay đổi tư duy. Nó không chỉ là học một API mới, mà là học cách thiết kế thuật toán cho phần cứng song song.
Từ ví dụ std::sort chậm chạp đến thrust::sort tốc độ, từ self-attention tiêu chuẩn đến FlashAttention, tất cả đều là kết quả của việc hiểu rõ "cỗ máy" mình đang chạy và tôn trọng các quy luật của nó—đặc biệt là quy luật về bộ nhớ.
Hi vọng bài viết này đã cho bạn một cái nhìn tổng quan về thế giới thú vị của tính toán GPU.
lượt xem
— lượt xem
Nguyen Xuan Hoa
nguyenxuanhoakhtn@gmail.com